Suppose that a scalar 
}")


")
In this article, we will study the estimation and hypothesis testing of 
1. The Algebra of Linear Regression
Given a sample of T values of 
^2 \ \ \ \ \ (2)")
The OLS estimate of
^{\!-1} \!\!\cdot\, \frac{1}{T}\sum_{t=1}^n x_ty_t. \ \ \ \ \ (3)")
The model is written in matrix notation as:
")
")
where 





Thus,
^{-1}X^Ty. \ \ \ \ \ (6)")
Similarly,
![\displaystyle \hat u = y - Xb = y - X(X^TX)^{-1}X^Ty = [I_T - X(X^TX)^{-1}X^T]y = M_Xy. \ \ \ \ \ (7)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat+u+%3D+y+-+Xb+%3D+y+-+X%28X%5ETX%29%5E%7B-1%7DX%5ETy+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5Dy+%3D+M_Xy.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0 "\displaystyle \hat u = y - Xb = y - X(X^TX)^{-1}X^Ty = [I_T - X(X^TX)^{-1}X^T]y = M_Xy. \ \ \ \ \ (7)")
where 
![\displaystyle M_X = [I_T - X(X^TX)^{-1}X^T]. \ \ \ \ \ (8)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5D.+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0 "\displaystyle M_X = [I_T - X(X^TX)^{-1}X^T]. \ \ \ \ \ (8)")
")
")
Since
")
Thus, we can verify that the sample residuals are orthogonal to
")
The sample residual is constructed from the sample estimate of
")
")
![\displaystyle \hat u = y - Xb = [I_T - X(X^TX)^{-1}X^T]y = M_Xy = M_XX b + u. \ \ \ \ \ (15)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat+u+%3D+y+-+Xb+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5Dy+%3D+M_Xy+%3D+M_XX+b+%2B+u.+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0 "\displaystyle \hat u = y - Xb = [I_T - X(X^TX)^{-1}X^T]y = M_Xy = M_XX b + u. \ \ \ \ \ (15)")
^{-1}X^Ty = (X^TX)^{-1}X^T(X\beta + u) = \beta + (X^TX)^{-1}X^Tu. \ \ \ \ \ (16)")
The fit of OLS is described in terms of 
}")
")
2. Assumptions on X and u
We shall assume that
(a) X will be deterministic
(b) 
(c)
2.1. Properties of Estimated b Under Above Assumptions
Since,
^{-1}X^Ty = (X^TX)^{-1}X^T(X\beta + u) = \beta + (X^TX)^{-1}X^Tu. \ \ \ \ \ (18)")
Taking expectations of both sides, we have,
 = \beta + (X^TX)^{-1}X^T\mathop{\mathbb E}(u) = \beta. \ \ \ \ \ (19)")
And the variance covariance matrix is given by,
![\displaystyle \mathop{\mathbb E}[(b - \beta)(b - \beta)^T] = \mathop{\mathbb E}[((X^TX)^{-1}X^Tu)((X^TX)^{-1}X^Tu)^T] = \sigma^2(X^TX)^{-1}. \ \ \ \ \ (20)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%28b+-+%5Cbeta%29%28b+-+%5Cbeta%29%5ET%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5B%28%28X%5ETX%29%5E%7B-1%7DX%5ETu%29%28%28X%5ETX%29%5E%7B-1%7DX%5ETu%29%5ET%5D+%3D+%5Csigma%5E2%28X%5ETX%29%5E%7B-1%7D.+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=0 "\displaystyle \mathop{\mathbb E}[(b - \beta)(b - \beta)^T] = \mathop{\mathbb E}[((X^TX)^{-1}X^Tu)((X^TX)^{-1}X^Tu)^T] = \sigma^2(X^TX)^{-1}. \ \ \ \ \ (20)")
Thus b is unbiased and is a linear function of y.
2.2. Distribution of Estimated b Under Above Assumptions
As u is Gaussian,
^{-1}X^Tu. \ \ \ \ \ (21)")
implies that b is also Gaussian.
^{-1}). \ \ \ \ \ (22)")
2.3. Properties of Estimated Sample Variance Under Above Assumptions
The OLS estimate of variance of u,
 = {\hat u}^T\hat u / (T - k) = u^TM_X^TM_Xu / (T - k) = u^TM_Xu / (T - k). \ \ \ \ \ (23)")
Since
")
where
")
and 
Since,
")
that is, since the two spaces that they represent are orthogonal to each other, it follows that:
")
whenever v is a column of X. Since we assume X to be of full rank, there are k such vectors and their eigenvalue is the right hand side, which is 0.
Also since
^{-1}X^T. \ \ \ \ \ (28)")
Thus, it follows that
")
whenever v is orthogonal to X. Since there are (T – k) such vectors,
Thus
")
Let
")
Then,
")
")
As these 
")
Also,
 = \mathop{\mathbb E}(P^Tu u^T P) = \sigma^2I_T. \ \ \ \ \ (35)")
Thus, elements of w are uncorrelated with each other, have mean 0 and variance
Since each w has expectation of
 = (T - k)\sigma^2. \ \ \ \ \ (36)")
Hence,
 = \sigma^2. \ \ \ \ \ (37)")
2.4. Distribution of Estimated Sample Variance Under Above Assumptions
Since
")
when u is Gaussian, w is also Gaussian.
Then,
")
implies that 
}")
Thus,
. \ \ \ \ \ (40)")
Also, b and 
![\displaystyle \mathop{\mathbb E}[\hat u(b - \beta)^T] = \mathop{\mathbb E}[M_Xu u^T X (X^TX)^{-1} = 0. \ \ \ \ \ (41)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Chat+u%28b+-+%5Cbeta%29%5ET%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5BM_Xu+u%5ET+X+%28X%5ETX%29%5E%7B-1%7D+%3D+0.+%5C+%5C+%5C+%5C+%5C+%2841%29&bg=ffffff&fg=000000&s=0 "\displaystyle \mathop{\mathbb E}[\hat u(b - \beta)^T] = \mathop{\mathbb E}[M_Xu u^T X (X^TX)^{-1} = 0. \ \ \ \ \ (41)")
Since b and 
2.5. t Tests about
We wish to test the hypothesis that the ith element of 

The t-statistic for testing this null hypothesis is
^2} \ \ \ \ \ (42)")
where 
^{-1}}")

Under the null hypothesis,
. \ \ \ \ \ (43)")
Thus,
. \ \ \ \ \ (44)")
Thus,
} / {\sqrt{\sigma^2 \xi^{ii}}}}{\sqrt{s^2 / \sigma^2 }} \ \ \ \ \ (45)")
Thus the numerator is N(0, 1) and the denominator is the square root of a chi-square distribution with (T – k) degrees of freedom. This gives a t-distribution to the variable on the left side.
2.6. F Tests about
To generalize what we did for t tests, consider that we have a matrix 

")
Since,
^{-1}). \ \ \ \ \ (47)")
Thus, under 
^{-1}R^T). \ \ \ \ \ (48)")
Theorem 1 If
is a
vector with
and non singular
, then
.
Applying the above theorem to the 
^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r) \sim \chi^2 (m). \ \ \ \ \ (49)")
Now consider,
^T (s^2R(X^TX)^{-1}R^T)^{-1}(Rb - r) / m. \ \ \ \ \ (50)")
where sigma has been replaced with the sample estimate s.
Thus,
![\displaystyle F = \frac{[(Rb - r)^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r)] / m}{[RSS / (T - k)]/ \sigma^2} \ \ \ \ \ (51)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F+%3D+%5Cfrac%7B%5B%28Rb+-+r%29%5ET+%28%5Csigma%5E2R%28X%5ETX%29%5E%7B-1%7DR%5ET%29%5E%7B-1%7D%28Rb+-+r%29%5D+%2F+m%7D%7B%5BRSS+%2F+%28T+-+k%29%5D%2F+%5Csigma%5E2%7D+%5C+%5C+%5C+%5C+%5C+%2851%29&bg=ffffff&fg=000000&s=0 "\displaystyle F = \frac{[(Rb - r)^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r)] / m}{[RSS / (T - k)]/ \sigma^2} \ \ \ \ \ (51)")
In the above, the numerator is a }")
}")
Hence, the variable on the left hand side has an exact }")
 is a fixed quantity, not a random variable.
is a fixed quantity, not a random variable. 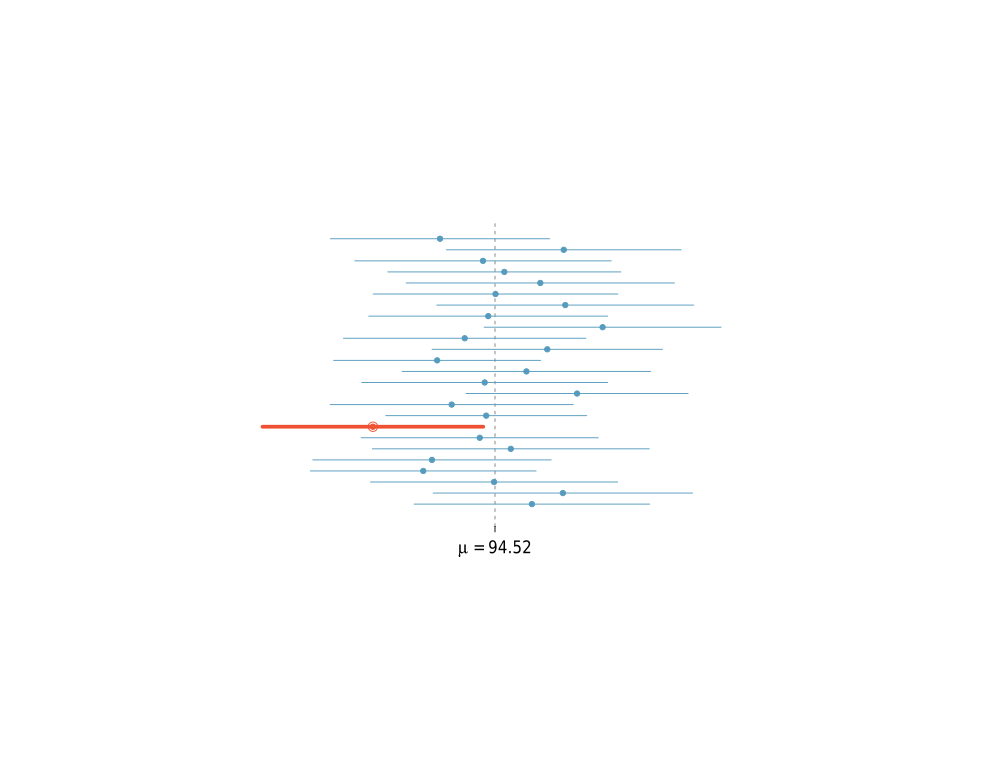
 .
.  . On day 3, you collect new data and construct a 95 percent confidence interval for an unrelated parameter
. On day 3, you collect new data and construct a 95 percent confidence interval for an unrelated parameter  .
.  .
.  into two disjoint sets
into two disjoint sets  and
and  and we wish to test:
and we wish to test: ")
 the alternate hypothesis.
the alternate hypothesis.  be its range. Let
be its range. Let  be the rejection region.
be the rejection region. = \mathbb{P}_{\theta}(X \in R) \ \ \ \ \ (2)")
). \ \ \ \ \ (3)")
 Test: A test with size less than or equal to
Test: A test with size less than or equal to  is called a simple hypothesis.
is called a simple hypothesis.  or
or  is called a composite hypothesis.
is called a composite hypothesis. ")
")
")
}") where
where  is known. We want to test
is known. We want to test  versus
versus  . Hence
. Hence ![{\Theta_0 = (- \infty, 0]}](http://s0.wp.com/latex.php?latex=%7B%5CTheta_0+%3D+%28-+%5Cinfty%2C+0%5D%7D&bg=ffffff&fg=000000&s=0 "{\Theta_0 = (- \infty, 0]}") and
and }") .
. ")
 .
.  : \overline{X} > c \} \ \ \ \ \ (8)")
 = \mathbb{P}_{\mu}(X \in R) \\ = \mathbb{P}_{\mu}(\overline{X} > c) \\ = \mathbb{P}_{\mu}\left( \frac{\sqrt{n}(\overline{X} - \mu)}{\sigma} > \frac{\sqrt{n}(c - \mu)}{\sigma} \right) \\ = \mathbb{P}_{\mu}\left( Z > \frac{\sqrt{n}(c - \mu)}{\sigma} \right) \\ = 1 - \Phi\left(\frac{\sqrt{n}(c - \mu)}{\sigma}\right). \ \ \ \ \ (9)")
) \\ = \underset{\mu \leq 0}{\text{sup}}\left(1 - \Phi\left(\frac{\sqrt{n}(c - \mu)}{\sigma}\right)\right) \\ = \beta(0) \\ = 1 - \Phi\left(\frac{c\sqrt{n}}{\sigma}\right). \ \ \ \ \ (10)")
. \ \ \ \ \ (11)")
}{\sqrt{n}}. \ \ \ \ \ (12)")
 . For a test size of 95%
. For a test size of 95% ")
")
 be \textsc{iid} random variables with
be \textsc{iid} random variables with }") . Let
. Let  be the estimate of
be the estimate of  be the standard deviation of the distribution of
be the standard deviation of the distribution of ")
. \ \ \ \ \ (16)")
 where
where ")
) \\ = \underset{\theta \in \Theta_0}{\text{sup}}\mathbb{P}_{\theta}(X \in R) \\ = \mathbb{P}_{\theta_0}(X \in R) \\ = \mathbb{P}_{\theta_0}(|W| > z_{\alpha/2}) \\ = \mathbb{P}_{\theta_0}\left(\left| \frac{\hat { \theta } - \theta_0 }{\widehat{\textsf{se}}}\right| > z_{\alpha/2}\right) \\ \rightarrow \mathbb{P}(|Z| > z_{\alpha/2}) \\ = \alpha. \ \ \ \ \ (18)")
 and
and  times, respectively, and have a probability of predicting with success as
times, respectively, and have a probability of predicting with success as  and
and  , respectively.
, respectively. .
.")
 versus
versus  is
is  = \frac{ \underset{\theta \in \Theta_0}{\text{sup}} (L( \theta|\mathbf{x} )) }{ \underset{\theta \in \Theta}{\text{sup}} (L( \theta|\mathbf{x} )) }. \ \ \ \ \ (20)")
 components:
components: }") . For
. For  ,
, moment as
moment as  = \mathbb{E}_\theta(X^j) = \int \mathrm{x}^{j}\,\mathrm{d}F_{\theta}(x). \ \ \ \ \ (1)")
")
 is the value of
is the value of  = \hat{\alpha_1} \\ \alpha_2(\hat{\theta_n}) = \hat{\alpha_2} \\ \vdots \vdots \vdots \\ \alpha_k(\hat{\theta_n}) = \hat{\alpha_k} \ \ \ \ \ (3)")
}") . The likelihood function is defined as
. The likelihood function is defined as  = \prod_{i=1}^n f_X(X_i;\theta). \ \ \ \ \ (4)")
 = \log(\mathcal{L}_n(\theta))}") .
. }") .
.}") distribution.
distribution.  = \begin{cases} 1/\theta 0 < x < \theta \\ 0 \text{otherwise}. \end{cases} \ \ \ \ \ (5)")
 and
and  , then
, then  = 0}") . Otherwise
. Otherwise  = (\frac{1}{\theta})^n }") which is a decreasing function of
which is a decreasing function of \} = X_{max}}") .
.  and
and  are \textsc{pdf}, the Kullback Leibler distance between them is defined as
are \textsc{pdf}, the Kullback Leibler distance between them is defined as  = \int f(x) \log \left( \frac{f(x) }{g(x) } \right) dx. \ \ \ \ \ (6)")
}") . Then the score function is defined as
. Then the score function is defined as  = \frac{\partial \log f_X(x; \theta) }{\partial \theta}. \ \ \ \ \ (7)")
 = \mathbb{V}_{\theta}\left( \sum_{i=1}^n s(X_i; \theta) \right) \\ = \sum_{i=1}^n \mathbb{V}_{\theta}\left(s(X_i; \theta) \right). \ \ \ \ \ (8)")
) = 0. \ \ \ \ \ (9)")
) = \mathbb{E}_{\theta}(s^2(X; \theta)). \ \ \ \ \ (10)")
 = nI(\theta). \ \ \ \ \ (11)")
 = -\mathbb{E}_{\theta}\left( \frac{\partial^2 \log f_X(x; \theta) }{\partial \theta^2} \right) \\ = -\int \left( \frac{\partial^2 \log f_X(x; \theta) }{\partial \theta^2} \right)f_X(x; \theta) dx. \ \ \ \ \ (12)")
 } }") .
. }. \ \ \ \ \ (13)")
. \ \ \ \ \ (14)")
}} }") .
. . \ \ \ \ \ (15)")
}") traps
traps  . We call
. We call  is random and
is random and }") .
. be the \textsc{cdf} of a random variable
be the \textsc{cdf} of a random variable  with standard normal distribution and
with standard normal distribution and  \\ \mathbb{P}(Z > z _{\alpha / 2} ) = ( 1 - \alpha / 2) \\ \mathbb{P}(- z _{\alpha / 2} < Z < z _{\alpha / 2}) = 1 - \alpha. \ \ \ \ \ (16)")
 \ \ \ \ \ (17)")
 \rightarrow 1 - \alpha. \ \ \ \ \ (18)")
 is .95,
is .95,  is 1.96 and the interval is thus
is 1.96 and the interval is thus  = \left( \hat{\theta} - 1.96\hat{\textsf{se}} , \hat{\theta} + 1.96\hat{\textsf{se}} \right) }") .
. : \theta \in \Theta\} \ \ \ \ \ (1)")
 = \frac{1}{\sigma\sqrt{2\pi}}exp\{-\frac{1}{2\sigma^2}(x-\mu)^2\}, \mu \in \mathbb{R}, \sigma > 0\} \ \ \ \ \ (2)")
 cannot be parameterized by a finite number of parameters.
cannot be parameterized by a finite number of parameters. is called a statistical functional.
is called a statistical functional.  is given as:
is given as:  = \int x dF(x) \ \ \ \ \ (3)")
 = \int x^2 dF(x) - \left(\int xdF(x)\right)^2 \ \ \ \ \ (4)")
 = F^{-1}(x) \ \ \ \ \ (5)")
,\dotsc,(X_n, Y_n)}") .
.  is assumed to depend on
is assumed to depend on  = \mathbb{E}(Y|X=x) \ \ \ \ \ (6)")
 is finite dimensional, then the model is a parametric regression model, otherwise it is a non-parametric regression model.
is finite dimensional, then the model is a parametric regression model, otherwise it is a non-parametric regression model.  , then we call this regression or curve estimation.
, then we call this regression or curve estimation.  = \mathbb{E}(Y|X=x)}") can be algebraically manipulated to express it in the form
can be algebraically manipulated to express it in the form  + \epsilon \ \ \ \ \ (7)")
 = 0}") .
. : \theta \in \Theta\}}") is a parametric model, then we write
is a parametric model, then we write  = \int_A f_X(x) dx }") to denote the probability that X belongs to A. It does not mean that we are averaging over
to denote the probability that X belongs to A. It does not mean that we are averaging over  . Since
. Since  : Formally, let
: Formally, let  of
of . \ \ \ \ \ (8)")
 = \mathbb{E}( \hat{\theta} ) - \theta. \ \ \ \ \ (9)")
 .
.  = \sqrt{\mathbb{V}(\hat{\theta})}. \ \ \ \ \ (10)")
 = \mathbb{E}_{ \theta } ( \hat{\theta} - \theta)^2. \ \ \ \ \ (11)")
 . Then,
. Then,  = p}") . Hence,
. Hence,  is unbiased.
is unbiased. . \ \ \ \ \ (12)")
}") (where
(where  }") and
and  }") are functions of the data), such that
are functions of the data), such that  \geq 1 - \alpha, \forall \: \theta \in \Theta. \ \ \ \ \ (13)")
 \\ \mathbb{P}(Z > z _{\alpha / 2} ) = ( 1 - \alpha / 2) \\ \mathbb{P}(- z _{\alpha / 2} < Z < z _{\alpha / 2}) = 1 - \alpha. \ \ \ \ \ (14)")
 \ \ \ \ \ (15)")
 \rightarrow 1 - \alpha. \ \ \ \ \ (16)")
 converges in probability to the distribution mean
converges in probability to the distribution mean  and let
and let  converges to
converges to  , if for every
, if for every  , we have
, we have  \rightarrow 0 \ \ \ \ \ (1)")
 .
. , if
, if  = F(t) \ \ \ \ \ (2)")
 for which
for which  be \textsc{iid} with mean
be \textsc{iid} with mean }") and variance
and variance }") . Let sample mean be defined as
. Let sample mean be defined as \sum_{i=1}^n X_i}") . It can be shown that
. It can be shown that  = \mu}") and
and  = \sigma^2/n}") .
. .
.  } { \sqrt{ \mathbb{V}( \overline{X}_n ) } } = \frac{ \sqrt{n}(\overline{X}_n - \mu) } { \sigma } \rightsquigarrow N(0,1) \ \ \ \ \ (3)")
 \\ \overline{X}_n \approx N\left(\mu, \frac{\sigma^2}{n}\right) \\ (\overline{X}_n - \mu) \approx N(0, \sigma^2/n) \\ \sqrt{n}(\overline{X}_n - \mu) \approx N(0,\sigma^2) \\ \frac{\sqrt{n}(\overline{X}_n - \mu)}{\sigma} \approx N(0,1). \ \ \ \ \ (4)")
^2\right). \ \ \ \ \ (5)")
}{S_n} \approx N(0,1). \ \ \ \ \ (6)")
 be a random variable with conditions of CLT met, and let
be a random variable with conditions of CLT met, and let }") be a differentiable function with
be a differentiable function with  \neq 0}") . Then,
. Then,  \\ \Longrightarrow \quad g(Y_n) \approx N\left(g(\mu), (g'(\mu))^2\frac{\sigma^2}{n}\right). \ \ \ \ \ (7)")
 = \int x f(x) dx = \begin{cases} \sum_x x f(x) X \text{ is discrete} \\ \int_x x f(x) dx X \text{ is continuous}. \end{cases} \ \ \ \ \ (1)")
 = \mathbb{E}X = \int x \thinspace dF(x) = \mu_X = \mu \ \ \ \ \ (2)")
}") , then the expectation of Y is
, then the expectation of Y is  = \int r(X) \thinspace dF_X(x). \ \ \ \ \ (3)")
 are constants, then
are constants, then  = \sum_{i=1}^na_i\mathbb{E}(X_i). \ \ \ \ \ (4)")
 = \prod_{i=1}^n\mathbb{E}(X_i). \ \ \ \ \ (5)")
}") ,
,  , or
, or  is defined by:
is defined by:  = \mathbb{E}((X - \mu)^2) = \int (X - \mu)^2 \thinspace dF(x) \ \ \ \ \ (6)")
. \ \ \ \ \ (7)")
^2\right). \ \ \ \ \ (8)")
 = \mathbb{E}(X^2) - \mu^2. \ \ \ \ \ (9)")
 and
and  = a^2 \mathbb{V}(X). \ \ \ \ \ (10)")
 = \sum_{i=1}^n{a_i}^2\mathbb{V}(X_i). \ \ \ \ \ (11)")
 = \mu, \quad \mathbb{V}(\overline{X}_n) = \frac{\sigma^2}{n} \quad \text{ and } \quad \mathbb{E}(S_n^2) = \sigma^2. \ \ \ \ \ (12)")
")
}") to outcomes
to outcomes  in
in  .
. ![{F_X \colon \mathbb{R} \rightarrow [0,1]}](http://s0.wp.com/latex.php?latex=%7BF_X+%5Ccolon+%5Cmathbb%7BR%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0 "{F_X \colon \mathbb{R} \rightarrow [0,1]}") defined by:
defined by:
 = \mathbb{P}(X \leq x) \ \ \ \ \ (2)")
 . If
. If  = G(x)}") for all
for all  then
then  = \mathbb{P}(Y \in A)}") for all
for all  .
.  = \mathbb{P}(X = x)}") .
.  such that
such that  \geq 0}") for all
for all dx = 1}")
 with
with  we have
we have
dx = \mathbb{P}(a < X < b) \ \ \ \ \ (3)")
 = \int_{-\infty}^x f_X(t)dt \ \ \ \ \ (4)")
 = F_X'(X)}") at all points for which
at all points for which  is differentiable.
is differentiable.  to denote that the random variable
to denote that the random variable  if
if  = 1}") . Hence
. Hence  = \begin{cases} 0& x < a \\ 1& x \geq a. \end{cases} \ \ \ \ \ (5)")
 be a given integer. Let
be a given integer. Let  = \begin{cases} 1/k & 1 \leq x \leq k \\ 0 & \text{otherwise}. \end{cases} \ \ \ \ \ (6)")
 .
. = p}") and
and  = 1 - p}") for some
for some ![{p \in [0, 1]}](http://s0.wp.com/latex.php?latex=%7Bp+%5Cin+%5B0%2C+1%5D%7D&bg=ffffff&fg=000000&s=0 "{p \in [0, 1]}") . We say that
. We say that }") . The probability function
. The probability function  = p^x(1 - p)^{(1 - x)} \text{ for } x \in {0, 1}}") .
. denotes the probability of getting heads in a single coin toss and the tosses are assumed to be independent then the \textsc{pdf} of
denotes the probability of getting heads in a single coin toss and the tosses are assumed to be independent then the \textsc{pdf} of  = \begin{cases} \begin{pmatrix} n \\ x \end{pmatrix} p^x(1 - p)^{(n-x)} & 0 \leq x \leq n \\ 0 & \text{otherwise}. \end{cases} \ \ \ \ \ (7)")
}") if
if  = p(1 - p)^{(x - 1)} \text{ for } x \in \{1, 2, 3, \dotsc , \}. \ \ \ \ \ (8)")
 , written as
, written as }") if
if  = e^{-\lambda}\frac{\lambda^{-x}}{x!} \text{ for } x \geq 0. \ \ \ \ \ (9)")
 , X has a uniform distribution over
, X has a uniform distribution over }") , if
, if ![\displaystyle f_X(x) = \begin{cases} \frac{1}{b - a} & x \in [a, b] \\ 0 & \text{otherwise}. \end{cases} \ \ \ \ \ (10)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle++f_X%28x%29+%3D+%5Cbegin%7Bcases%7D+%5Cfrac%7B1%7D%7Bb+-+a%7D+%26+x+%5Cin+%5Ba%2C+b%5D+%5C%5C+0+%26+%5Ctext%7Botherwise%7D.+%5Cend%7Bcases%7D+%5C+%5C+%5C+%5C+%5C+%2810%29&bg=ffffff&fg=000000&s=0 "\displaystyle f_X(x) = \begin{cases} \frac{1}{b - a} & x \in [a, b] \\ 0 & \text{otherwise}. \end{cases} \ \ \ \ \ (10)")
}") if
if  = \frac{1}{\sigma\sqrt{2\pi}}exp\left\{-\frac{1}{2\sigma^2}(x-\mu)^2\right\}, \text{ where } \mu, \sigma \in \mathbb{R}, \sigma > 0. \ \ \ \ \ (11)")
 and
and  . A standard Normal random variable is denoted by
. A standard Normal random variable is denoted by }") and
and }") . The \textsc{pdf} is plotted in Figure There is no closed-form expression for
. The \textsc{pdf} is plotted in Figure There is no closed-form expression for  / \sigma \sim N(0, 1)}") .
.
}") , then
, then }") .
.
}") for
for  are independent, then we have
are independent, then we have
. \ \ \ \ \ (12)")
}") that if
that if  \ \ \ \ \ (13)")
 = \mathbb{P}\left(a < \mu + \sigma Z < b\right) \ \ \ \ \ (14)")
 = \mathbb{P}\left(\frac{a - \mu}{\sigma} < Z < \frac{b - \mu}{\sigma}\right) \ \ \ \ \ (15)")
 = \Phi\left(\frac{b - \mu}{\sigma}\right) - \Phi\left(\frac{a - \mu}{\sigma}\right). \ \ \ \ \ (16)")
}") . Find
. Find }") .
. \\ = \mathbb{P}\left(3 + Z\sqrt{5} > 1\right) \\ = \mathbb{P}\left( Z > \frac{-2}{\sqrt{5}}\right) \\ = 1 - \Phi\left(\frac{2}{\sqrt{5}}\right) \\ = 1 - \Phi\left(0.894427\right) \\ = 0.81. \ \ \ \ \ (17)")
 of
of  = .2}") . Solution:
. Solution:  \\ = \mathbb{P}\left(3 + Z\sqrt{5} < x\right) \\ = \mathbb{P}\left(Z < \frac{x - 3}{\sqrt{5}}\right) \\ = \Phi\left(\frac{x - 3}{\sqrt{5}}\right) \ \ \ \ \ (18)")
 = 0.2}")
 = \Phi\left(\frac{x - 3}{\sqrt{5}}\right) \\ -0.8416 = \left(\frac{x - 3}{\sqrt{5}}\right) \\ x = \left(3 - 0.8416\times\sqrt{5}\right) \\ x = 1.1181. \ \ \ \ \ (19)")
 , written as
, written as }") , if
, if  = \frac{1}{\beta}e^{-x/\beta}, \text{ for } x > 0. \ \ \ \ \ (20)")
 , the Gamma function is defined as
, the Gamma function is defined as  = \int_0^\infty y^{\alpha - 1} e^{-y} dy. \ \ \ \ \ (21)")
 ), written as
), written as }") , if
, if  = \frac{1}{\beta^{\alpha}\Gamma(\alpha)}x^{\alpha - 1}e^{-x/\beta}, \text{ for } x > 0. \ \ \ \ \ (22)")
 = \mathbb{P}(X = x, Y = y)}")
 a \textsc{pdf} of random variables
a \textsc{pdf} of random variables }") if
if  \geq 0}") for all
for all  \in \mathbb{R}^2}") ,
,
 \thinspace dx \thinspace dy = 1}")
 we have
we have
 \thinspace dx \thinspace dy = \mathbb{P}((X,Y) \in A). \ \ \ \ \ (23)")
 , let
, let  = \begin{cases} cx^2y x^2 \leq y \leq 1, \\ 0 \text{otherwise}. \end{cases} \ \ \ \ \ (24)")
 .
. to
to  and find
and find  \thinspace dy \thinspace dx \\ = \int_{-1}^{1}\int_{x^2}^{1}f_{X,Y}(x, y) \thinspace dy \thinspace dx \\ = \int_{-1}^{1}\int_{x^2}^{1}cyx^2 \thinspace dy \thinspace dx \\ = \int_{-1}^{1}c\left(\frac{1 - x^4}{2}\right)x^2 \thinspace dx \\ = \left(\frac{c}{2}\right)\left(\int_{-1}^{1}x^2 \thinspace dx - \int_{-1}^{1}x^6 \thinspace dx \right)\\ = \left(\frac{c}{2}\right)\left( \frac{2}{3} - \frac{2}{7}\right)\\ = \left(\frac{4c}{21}\right) \\ c = \frac{21}{4} \ \ \ \ \ (25)")
 have a joint mass distribution
have a joint mass distribution  then the marginal distribution of
then the marginal distribution of  = \mathbb{P}(X = x) = \sum_y \mathbb{P}(X = x, Y = y) = \sum_y f_{X,Y}(x, y) \ \ \ \ \ (26)")
 = \mathbb{P}(Y = y) = \sum_x \mathbb{P}(X = x, Y = y) = \sum_x f_{X,Y}(x, y) \ \ \ \ \ (27)")
 = \int f_{X,Y}(x, y) \thinspace dy \ \ \ \ \ (28)")
 = \int f_{X,Y}(x, y) \thinspace dx \ \ \ \ \ (29)")
 we have
we have  = \mathbb{P}(X \in A)\mathbb{P}(Y \in B) \ \ \ \ \ (30)")
 if
if  = f_X(x)f_Y(y)}") for all values of
for all values of  = \frac{f_{X, Y}(x, y)}{f_Y(y)} \ \ \ \ \ (31)")
 where
where }") denote their \textsc{pdf}. We say that
denote their \textsc{pdf}. We say that  ,
,  = \prod_{i=1}^n \mathbb{P}(X_i \in A_i) \ \ \ \ \ (32)")
")
 . We also call
. We also call ")
}") are independent. The joint density of
are independent. The joint density of  = \frac{1}{{(2\pi)}^{k/2}}\text{exp}\biggl\{-\frac{1}{2}\sum_{j=1}^k {z_j}^2\biggr\} = \frac{1}{{(2\pi)}^{k/2}}\text{exp}\left\{-\frac{1}{2}z^Tz\right\} \\ f_X(x;\mu, \Sigma) = \frac{1}{{(2\pi)}^{k/2}{|\Sigma |}^{1/2}}\text{exp}\left\{-\frac{1}{2}(x - \mu)^T\Sigma^{-1}(x - \mu)\right\} \ \ \ \ \ (35)")
 and the event that the first toss is heads is
and the event that the first toss is heads is  .
.  is the false event.
is the false event.  are mutually exclusive events if
are mutually exclusive events if  whenever
whenever  .
.  is called a probability measure or a probability distribution if it satisfies the following three axioms:
is called a probability measure or a probability distribution if it satisfies the following three axioms:
 = 1}") .
.
 \geq 0}") for every
for every  are disjoint, then:
are disjoint, then:
 = \sum_{i=1}^{\infty}\mathbb{P}(A_i) \ \ \ \ \ (2)")
 = 0 \ \ \ \ \ (3)")
 \leq \mathbb{P}(B) \ \ \ \ \ (4)")
 \leq 1 \ \ \ \ \ (5)")
 = 1 - \mathbb{P}(A) \ \ \ \ \ (6)")
 = \mathbb{P}(A) + \mathbb{P}(B) \ \ \ \ \ (7)")
 = \mathbb{P}(A) + \mathbb{P}(B) - \mathbb{P}\left(A \bigcap B\right) \ \ \ \ \ (8)")
 , then
, then  \rightarrow \mathbb{P}(A) \ \ \ \ \ (9)")
 is finite and each outcome is equally likely, then:
is finite and each outcome is equally likely, then:  = \frac{|A|}{|\Omega|} \ \ \ \ \ (10)")
 \times n \ \ \ \ \ (11)")
}") out of them is
out of them is !} \ \ \ \ \ (12)")
!} = \frac{20 \times 19 \times 18}{1 \times 2 \times 3} = 1140 \ \ \ \ \ (13)")
 = \mathbb{P}(A)\mathbb{P}(B) \ \ \ \ \ (14)")
 is independent if
is independent if  = \prod_{i \in J} \left(\mathbb{P}(A_i)\right) \ \ \ \ \ (15)")
 of
of  .
.  = \frac{\mathbb{P}(A \bigcap B)}{\mathbb{P}(B)}. \ \ \ \ \ (16)")
}") is the fraction of times
is the fraction of times  = \mathbb{P}(A)}") . Also, for any pair of events
. Also, for any pair of events  = \mathbb{P}(A|B)\mathbb{P}(B) = \mathbb{P}(B|A)\mathbb{P}(A). \ \ \ \ \ (17)")
 be a partition of
be a partition of  = \sum_{i=1}^n \mathbb{P}(B|A_i)\mathbb{P}(A_i). \ \ \ \ \ (18)")
 > 0 }") for each
for each  . If
. If  > 0}") , then for each
, then for each  :
:
 = \frac{\mathbb{P}(B|A_i)\mathbb{P}(A_i)}{\sum_{j=1}^n \mathbb{P}(B|A_j)\mathbb{P}(A_j)}. \ \ \ \ \ (19)")
 : The probability of the partition events given the single event
: The probability of the partition events given the single event  : The probability of the single event
: The probability of the single event  are the events that an email is spam, low priority or high priority, respectively. Let
are the events that an email is spam, low priority or high priority, respectively. Let  = .7, \thinspace \mathbb{P}(A_2) = .2, \text{ and } \mathbb{P}(A_3) = .1 }") .
.  = .9, \thinspace \mathbb{P}(B|A_2) = .02, \text{ and } \mathbb{P}(B|A_3) = .01 }") .
.  = \mathbb{P}(A_1|B) \ \ \ \ \ (20)")
 = \frac{\mathbb{P}(B|A_1)\mathbb{P}(A_1)}{\sum_{j=1}^3 \mathbb{P}(B|A_j)\mathbb{P}(A_j)} = \frac{.9 \times .7}{.9 \times .7 + .01 \times .2 + .01 \times .1} = .995. \ \ \ \ \ (21)")