Category: Statistics
Protected: Fisher Discriminant
Raising Abstraction Level in SAS
In the following codes an attempt is made to raise the abstraction level available to the sas programmer by providing list manipulation macros:
Markov Model for Loss Forecasting – Implementation in SAS
Here’s the sas code that implements the markov model for loss forecasting:
The Need For MapReduce and NoSQL
The Need for MapReduce
Relational Database Management Systems have been in use since 1970s. They provide the SQL language interface.
They are good at needle in the haystack problems – finding small results from big datasets.
They provide a number of advantages:
- A declarative query language
- Schemas
- Logical Data Independence
- Database Indexing
- Optimizations Through Use of Relational Algebra
- Views
- Acid Properties (Atomicity, Consistency, Isolation and Durability)
They provide scalability in the sense that even if the data doesn’t fit in main memory, the query will finish efficiently.
However, they are not good at scalability in another sense – that is, having multiple machines available, or multi-cores available will not reduce the time the query takes.
The need thus arose for a system which gives scalability when more machines are added and is thus able to process huge datasets (in 50 GB or more range).
The NoSQL databases give up on atleast one of the ACID properties to achieve better performance on parallel and/or distributed hardware.
Introduction to Hadoop
Apache Hadoop is a software framework for distributed processing of very large datasets.
It provides a distributed storage system Hadoop Distributed File System (HDFS)), and a processing part of the system MapReduce.
The system is so designed so as to recover from hardware failures in some nodes that make up the distributed cluster.
Hadoop is itself written in Java. There are interfaces to use the framework from other languages.
Files on hadoop system are stored in a distributed manner. They are split into blocks which are then stored on different nodes.
The map and reduce functions that a user of hadoop framework writes are packaged and sent to different nodes where they are processed in parallel.
Architecture
The Hadoop framework is composed of the following four modules:
- Hadoop Common: – The libraries needed by the other Hadoop modules;
- Hadoop Distributed File System (HDFS): A distributed file-system that stores data on commodity machines.
- Hadoop YARN: A platform responsible for managing computing resources in clusters.
- Hadoop MapReduce: A programming model for large scale data processing.
HDFS
Files in HDFS are broken into blocks. The default block size is 64MB.
An HDFS cluster has two types of nodes – namenode (it works as the master node) and a number of datanodes (these work as the worker nodes).
The namenodes manages the filesystem namespace, maintains the filesystem tree, and the metadata of each file.
The user does not directly have to interact with the namenode or datanodes. A client does that on the user’s behalf. The client also provides a POSIX like filesystem interface.
MapReduce Engine
The MapReduce Engine sits on top of the HDFS filesystem. It consists of one JobTracker and a TaskTracker. The MapReduce jobs of the client applications are submitted to the JobTracker, which pushes the work to the available TaskTracker nodes in the cluster.
The filesystem is designed such that the JobTracker can know the nodes that contain the data, and how far they are.
The TaskTracker communicates with the JobTracker every few minutes to check its status.
The Job Tracker and TaskTracker expose their status and information through Jetty. This can be viewed from a web browser.
By default Hadoop uses FIFO scheduling. The job scheduler in modern versions is separate and it is possible to use an alternate scheduler (eg. Fair scheduler , Capacity scheduler).
The Hadoop Ecosystem
The term “Hadoop” now refers not just to the 4 base modules above, but also to the ecosystem, or collection of additional software packages that can be installed on top of or alongside Hadoop.
Examples of these are
Impala,
Apache Sqoop,
Difference Equations
1. Difference Equations
1.1. Introduction
Time series analysis deals with a series of random variables.
1.2. First Order Difference Equations
We will study time indexed random variables 
Let 

")
Equation 1 is a linear first-order difference equation. It is a first-order difference equation because
In this chapter, we treat
1.3. Solution by Recursive Substitution
The equations are:

By recursively substituting we obtain:
")
1.4. Dynamic Multipliers
We want to know the effect of increasing 
")
2. pth-Order Difference Equations
We generalize the above dynamic system to let the value of y to depend on p of its own lags in addition to the current value of the input variable
")
We will rewrite the above p-th order equation to a vector first order equation.
We define,
")
")
")
")
or,
")
Following the approach taken for solving first order difference equation and applying it to the vector equation, we get,
")
3. General Solution of a p-th Order Difference Equation
If the eigenvalues of F matrix are distinct then we can write F as
")
")
where T is a non-singular matrix.
Thus,
")
and
")
In general,
")
and
")
Misconceptions About P Values and The History of Hypothesis Testing
1. Introduction
The misconceptions surrounding p values are an example where knowing the history of the field and the mathematical and philosophical principles behind it can greatly help in understanding.
The classical statistical testing of today is a hybrid of the approaches taken by R. A. Fisher on the one hand and Jerzy Neyman and Egon Pearson on the other.
P-value is often confused with the Type I error rate – 
In statistics journals and research, the Neyman-Pearson approach replaced the significance testing paradigm 60 years ago, but in empirical work the Fisher approach is pervasive.
The statistical testing approach found in the textbooks on statistics is a hybrid
2. Fisher’s Significance Testing
Fisher held the belief that statistics could be used for inductive inference, that “it is possible to argue from consequences to causes, from observations to hypothesis” and that it it possible to draw inferences from the particular to the general.
Hence he rejected the methods in which probability of a hypothesis given the data, }")
In his approach, the discrepancies in the data are used to reject the null hypothesis. This is done as follows:
The researcher sets up a null hypothesis, which is the status quo belief.
The sampling distribution under the null hypothesis is known.
If the observed data deviates from the mean of the sampling distribution by more than a specified level, called the level of significance, then we reject the null hypothesis. Otherwise, we “fail to reject” the null hypothesis.
The p-value in this approach is the probability of observing data at least as favorable to the alternative hypothesis as our current data set, if the null hypothesis is true.
There is a common misconception that if 
This is clearly false, and can be seen from the definition as the P value is calculated under the assumption that the null hypothesis is true. It therefore cannot be a probability of the null hypothesis being false.
Conversely, a p value being high merely means that a null effect is statistically consistent with the observed results.
It does not mean that the null hypothesis is true. We only fail to reject, if we adopt the data based inductive approach.
We need to consider the Type I and Type II error probabilities to draw such conclusions, which is done in the Neyman-Pearson approach.
3. Neyman-Pearson Theory
The main contribution of Neyman-Pearson hypothesis testing framework (they named it to distinguish it from the inductive approach of Fisher’s significance testing) is the introduction of the
- probabilities of committing two kinds of errors, false rejection (Type I error), called
, of the null hypothesis.
- power of a statistical test. It is defined as the probability of rejecting a false null hypothesis. It is equal to
.
Fisher’s theory relied on the rejection of null hypothesis based on the data, assuming null hypothesis to be true. In contrast, the Neyman-Pearson approach provides rules to make decisions to choose the between the two hypothesis.
Neyman–Pearson theory, then, replaces the idea of inductive reasoning with that of, what they called, inductive behavior.
In his own words, inductive behaviour was meant to imply: “The term ‘inductive behavior’ means simply the habit of humans and other animals (Pavlov’s dog, etc.) to adjust their actions to noticed frequencies of events, so as to avoid undesirable consequences”.
Then, in this approach, the costs associated with Type I and Type II behaviour determine the decision to accpet or reject. These costs vary from experiment to experiment and this thus is the main advantage of the Neyman-Pearson approach over Fisher’s approach.
Thus while designing the experiment the researcher has to control the probabilities of Type I and Type II errors. The best test is the one that minimizes the Type II error given an upper bound on the Type I error.
And what adds to the source of confusion is the fact that Neyman called the Type I error the level of significance, a term that Fisher used to denote the p values.
Ordinary Least Squares Under Standard Assumptions
Suppose that a scalar }")


")
In this article, we will study the estimation and hypothesis testing of
1. The Algebra of Linear Regression
Given a sample of T values of 
^2 \ \ \ \ \ (2)")
The OLS estimate of
^{\!-1} \!\!\cdot\, \frac{1}{T}\sum_{t=1}^n x_ty_t. \ \ \ \ \ (3)")
The model is written in matrix notation as:
")
")
where 





Thus,
^{-1}X^Ty. \ \ \ \ \ (6)")
Similarly,
![\displaystyle \hat u = y - Xb = y - X(X^TX)^{-1}X^Ty = [I_T - X(X^TX)^{-1}X^T]y = M_Xy. \ \ \ \ \ (7)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat+u+%3D+y+-+Xb+%3D+y+-+X%28X%5ETX%29%5E%7B-1%7DX%5ETy+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5Dy+%3D+M_Xy.+%5C+%5C+%5C+%5C+%5C+%287%29&bg=ffffff&fg=000000&s=0 "\displaystyle \hat u = y - Xb = y - X(X^TX)^{-1}X^Ty = [I_T - X(X^TX)^{-1}X^T]y = M_Xy. \ \ \ \ \ (7)")
where 
![\displaystyle M_X = [I_T - X(X^TX)^{-1}X^T]. \ \ \ \ \ (8)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+M_X+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5D.+%5C+%5C+%5C+%5C+%5C+%288%29&bg=ffffff&fg=000000&s=0 "\displaystyle M_X = [I_T - X(X^TX)^{-1}X^T]. \ \ \ \ \ (8)")
")
")
Since
")
Thus, we can verify that the sample residuals are orthogonal to
")
The sample residual is constructed from the sample estimate of
")
")
![\displaystyle \hat u = y - Xb = [I_T - X(X^TX)^{-1}X^T]y = M_Xy = M_XX b + u. \ \ \ \ \ (15)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Chat+u+%3D+y+-+Xb+%3D+%5BI_T+-+X%28X%5ETX%29%5E%7B-1%7DX%5ET%5Dy+%3D+M_Xy+%3D+M_XX+b+%2B+u.+%5C+%5C+%5C+%5C+%5C+%2815%29&bg=ffffff&fg=000000&s=0 "\displaystyle \hat u = y - Xb = [I_T - X(X^TX)^{-1}X^T]y = M_Xy = M_XX b + u. \ \ \ \ \ (15)")
^{-1}X^Ty = (X^TX)^{-1}X^T(X\beta + u) = \beta + (X^TX)^{-1}X^Tu. \ \ \ \ \ (16)")
The fit of OLS is described in terms of 
}")
")
2. Assumptions on X and u
We shall assume that
(a) X will be deterministic
(b) 
(c)
2.1. Properties of Estimated b Under Above Assumptions
Since,
^{-1}X^Ty = (X^TX)^{-1}X^T(X\beta + u) = \beta + (X^TX)^{-1}X^Tu. \ \ \ \ \ (18)")
Taking expectations of both sides, we have,
 = \beta + (X^TX)^{-1}X^T\mathop{\mathbb E}(u) = \beta. \ \ \ \ \ (19)")
And the variance covariance matrix is given by,
![\displaystyle \mathop{\mathbb E}[(b - \beta)(b - \beta)^T] = \mathop{\mathbb E}[((X^TX)^{-1}X^Tu)((X^TX)^{-1}X^Tu)^T] = \sigma^2(X^TX)^{-1}. \ \ \ \ \ (20)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%28b+-+%5Cbeta%29%28b+-+%5Cbeta%29%5ET%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5B%28%28X%5ETX%29%5E%7B-1%7DX%5ETu%29%28%28X%5ETX%29%5E%7B-1%7DX%5ETu%29%5ET%5D+%3D+%5Csigma%5E2%28X%5ETX%29%5E%7B-1%7D.+%5C+%5C+%5C+%5C+%5C+%2820%29&bg=ffffff&fg=000000&s=0 "\displaystyle \mathop{\mathbb E}[(b - \beta)(b - \beta)^T] = \mathop{\mathbb E}[((X^TX)^{-1}X^Tu)((X^TX)^{-1}X^Tu)^T] = \sigma^2(X^TX)^{-1}. \ \ \ \ \ (20)")
Thus b is unbiased and is a linear function of y.
2.2. Distribution of Estimated b Under Above Assumptions
As u is Gaussian,
^{-1}X^Tu. \ \ \ \ \ (21)")
implies that b is also Gaussian.
^{-1}). \ \ \ \ \ (22)")
2.3. Properties of Estimated Sample Variance Under Above Assumptions
The OLS estimate of variance of u,
 = {\hat u}^T\hat u / (T - k) = u^TM_X^TM_Xu / (T - k) = u^TM_Xu / (T - k). \ \ \ \ \ (23)")
Since
")
where
")
and 
Since,
")
that is, since the two spaces that they represent are orthogonal to each other, it follows that:
")
whenever v is a column of X. Since we assume X to be of full rank, there are k such vectors and their eigenvalue is the right hand side, which is 0.
Also since
^{-1}X^T. \ \ \ \ \ (28)")
Thus, it follows that
")
whenever v is orthogonal to X. Since there are (T – k) such vectors,
Thus
")
Let
")
Then,
")
")
As these 
")
Also,
 = \mathop{\mathbb E}(P^Tu u^T P) = \sigma^2I_T. \ \ \ \ \ (35)")
Thus, elements of w are uncorrelated with each other, have mean 0 and variance
Since each w has expectation of
 = (T - k)\sigma^2. \ \ \ \ \ (36)")
Hence,
 = \sigma^2. \ \ \ \ \ (37)")
2.4. Distribution of Estimated Sample Variance Under Above Assumptions
Since
")
when u is Gaussian, w is also Gaussian.
Then,
")
implies that 
}")
Thus,
. \ \ \ \ \ (40)")
Also, b and 
![\displaystyle \mathop{\mathbb E}[\hat u(b - \beta)^T] = \mathop{\mathbb E}[M_Xu u^T X (X^TX)^{-1} = 0. \ \ \ \ \ (41)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathop%7B%5Cmathbb+E%7D%5B%5Chat+u%28b+-+%5Cbeta%29%5ET%5D+%3D+%5Cmathop%7B%5Cmathbb+E%7D%5BM_Xu+u%5ET+X+%28X%5ETX%29%5E%7B-1%7D+%3D+0.+%5C+%5C+%5C+%5C+%5C+%2841%29&bg=ffffff&fg=000000&s=0 "\displaystyle \mathop{\mathbb E}[\hat u(b - \beta)^T] = \mathop{\mathbb E}[M_Xu u^T X (X^TX)^{-1} = 0. \ \ \ \ \ (41)")
Since b and 
2.5. t Tests about
We wish to test the hypothesis that the ith element of 

The t-statistic for testing this null hypothesis is
^2} \ \ \ \ \ (42)")
where 
^{-1}}")

Under the null hypothesis,
. \ \ \ \ \ (43)")
Thus,
. \ \ \ \ \ (44)")
Thus,
} / {\sqrt{\sigma^2 \xi^{ii}}}}{\sqrt{s^2 / \sigma^2 }} \ \ \ \ \ (45)")
Thus the numerator is N(0, 1) and the denominator is the square root of a chi-square distribution with (T – k) degrees of freedom. This gives a t-distribution to the variable on the left side.
2.6. F Tests about
To generalize what we did for t tests, consider that we have a matrix 

")
Since,
^{-1}). \ \ \ \ \ (47)")
Thus, under 
^{-1}R^T). \ \ \ \ \ (48)")
Theorem 1 If
is a
vector with
and non singular
, then
.
Applying the above theorem to the 
^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r) \sim \chi^2 (m). \ \ \ \ \ (49)")
Now consider,
^T (s^2R(X^TX)^{-1}R^T)^{-1}(Rb - r) / m. \ \ \ \ \ (50)")
where sigma has been replaced with the sample estimate s.
Thus,
![\displaystyle F = \frac{[(Rb - r)^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r)] / m}{[RSS / (T - k)]/ \sigma^2} \ \ \ \ \ (51)](http://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F+%3D+%5Cfrac%7B%5B%28Rb+-+r%29%5ET+%28%5Csigma%5E2R%28X%5ETX%29%5E%7B-1%7DR%5ET%29%5E%7B-1%7D%28Rb+-+r%29%5D+%2F+m%7D%7B%5BRSS+%2F+%28T+-+k%29%5D%2F+%5Csigma%5E2%7D+%5C+%5C+%5C+%5C+%5C+%2851%29&bg=ffffff&fg=000000&s=0 "\displaystyle F = \frac{[(Rb - r)^T (\sigma^2R(X^TX)^{-1}R^T)^{-1}(Rb - r)] / m}{[RSS / (T - k)]/ \sigma^2} \ \ \ \ \ (51)")
In the above, the numerator is a }")
}")
Hence, the variable on the left hand side has an exact }")
Confidence Interval Interpretation
In frequentist statistics (which is one the used by journals and academia), 
Hence, a confidence interval is not a probability statement about
A 95 percent confidence interval does not mean that the interval would capture the true value 95 percent of the time. This statement would be absurd, because the experiment is conducted after assuming that the
A sample taken from a population cannot make probability statements about
The 95 in a 95 percent confidence interval only serves to give us the percentage of time the confidence interval would be right, across trials of all possible experiments, including the ones which are not about this
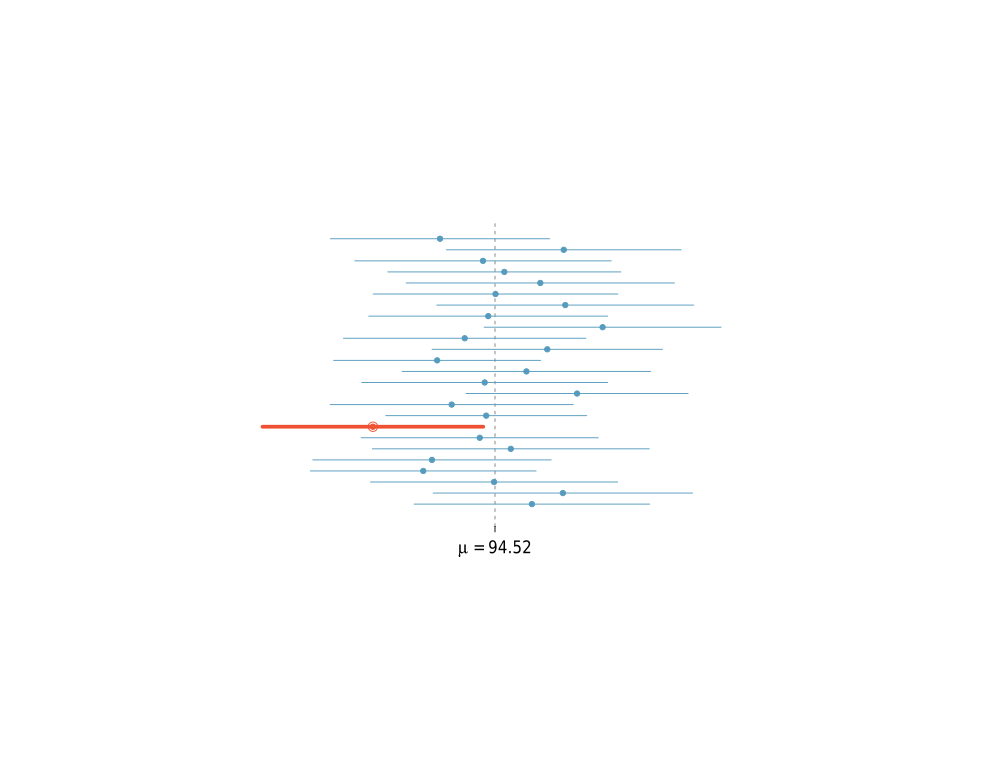
As an example, on day 1, you collect data and construct a 95 percent confidence interval for a parameter 
On day 2, you collect new data and construct a 95 percent confidence interval for an unrelated parameter 

You continue this way constructing confidence intervals for a sequence of unrelated parameters 
Then 95 percent of your intervals will trap the true parameter value.