1. Introduction
The misconceptions surrounding p values are an example where knowing the history of the field and the mathematical and philosophical principles behind it can greatly help in understanding.
The classical statistical testing of today is a hybrid of the approaches taken by R. A. Fisher on the one hand and Jerzy Neyman and Egon Pearson on the other.
P-value is often confused with the Type I error rate – 
In statistics journals and research, the Neyman-Pearson approach replaced the significance testing paradigm 60 years ago, but in empirical work the Fisher approach is pervasive.
The statistical testing approach found in the textbooks on statistics is a hybrid
2. Fisher’s Significance Testing
Fisher held the belief that statistics could be used for inductive inference, that “it is possible to argue from consequences to causes, from observations to hypothesis” and that it it possible to draw inferences from the particular to the general.
Hence he rejected the methods in which probability of a hypothesis given the data, }")
In his approach, the discrepancies in the data are used to reject the null hypothesis. This is done as follows:
The researcher sets up a null hypothesis, which is the status quo belief.
The sampling distribution under the null hypothesis is known.
If the observed data deviates from the mean of the sampling distribution by more than a specified level, called the level of significance, then we reject the null hypothesis. Otherwise, we “fail to reject” the null hypothesis.
The p-value in this approach is the probability of observing data at least as favorable to the alternative hypothesis as our current data set, if the null hypothesis is true.
There is a common misconception that if 
This is clearly false, and can be seen from the definition as the P value is calculated under the assumption that the null hypothesis is true. It therefore cannot be a probability of the null hypothesis being false.
Conversely, a p value being high merely means that a null effect is statistically consistent with the observed results.
It does not mean that the null hypothesis is true. We only fail to reject, if we adopt the data based inductive approach.
We need to consider the Type I and Type II error probabilities to draw such conclusions, which is done in the Neyman-Pearson approach.
3. Neyman-Pearson Theory
The main contribution of Neyman-Pearson hypothesis testing framework (they named it to distinguish it from the inductive approach of Fisher’s significance testing) is the introduction of the
- probabilities of committing two kinds of errors, false rejection (Type I error), called
, of the null hypothesis.
- power of a statistical test. It is defined as the probability of rejecting a false null hypothesis. It is equal to
.
Fisher’s theory relied on the rejection of null hypothesis based on the data, assuming null hypothesis to be true. In contrast, the Neyman-Pearson approach provides rules to make decisions to choose the between the two hypothesis.
Neyman–Pearson theory, then, replaces the idea of inductive reasoning with that of, what they called, inductive behavior.
In his own words, inductive behaviour was meant to imply: “The term ‘inductive behavior’ means simply the habit of humans and other animals (Pavlov’s dog, etc.) to adjust their actions to noticed frequencies of events, so as to avoid undesirable consequences”.
Then, in this approach, the costs associated with Type I and Type II behaviour determine the decision to accpet or reject. These costs vary from experiment to experiment and this thus is the main advantage of the Neyman-Pearson approach over Fisher’s approach.
Thus while designing the experiment the researcher has to control the probabilities of Type I and Type II errors. The best test is the one that minimizes the Type II error given an upper bound on the Type I error.
And what adds to the source of confusion is the fact that Neyman called the Type I error the level of significance, a term that Fisher used to denote the p values.
 is a fixed quantity, not a random variable.
is a fixed quantity, not a random variable. 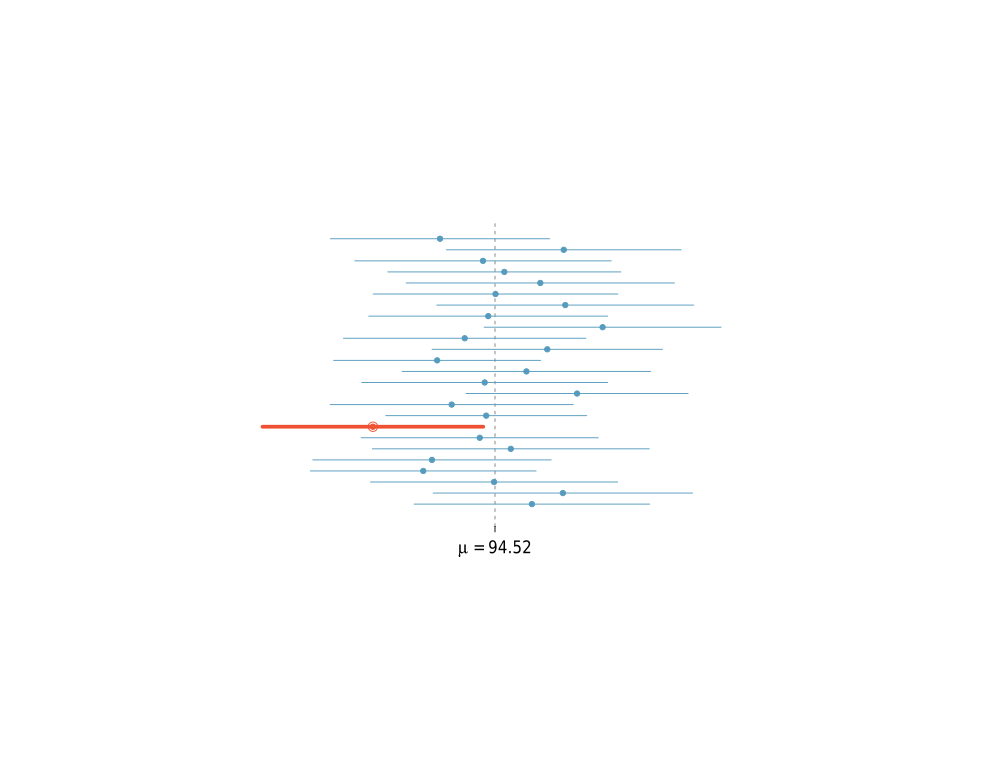
 .
.  . On day 3, you collect new data and construct a 95 percent confidence interval for an unrelated parameter
. On day 3, you collect new data and construct a 95 percent confidence interval for an unrelated parameter  .
.  .
.  into two disjoint sets
into two disjoint sets  and
and  and we wish to test:
and we wish to test: ")
 the null hypothesis and
the null hypothesis and  the alternate hypothesis.
the alternate hypothesis.  be a random variable and let
be a random variable and let  be its range. Let
be its range. Let  be the rejection region.
be the rejection region. and reject when it does.
and reject when it does.  = \mathbb{P}_{\theta}(X \in R) \ \ \ \ \ (2)")
). \ \ \ \ \ (3)")
 is called a simple hypothesis.
is called a simple hypothesis.  or
or  is called a composite hypothesis.
is called a composite hypothesis. ")
")
")
}") where
where  is known. We want to test
is known. We want to test  versus
versus  . Hence
. Hence ![{\Theta_0 = (- \infty, 0]}](http://s0.wp.com/latex.php?latex=%7B%5CTheta_0+%3D+%28-+%5Cinfty%2C+0%5D%7D&bg=ffffff&fg=000000&s=0 "{\Theta_0 = (- \infty, 0]}") and
and }") .
. ")
 .
.  : \overline{X} > c \} \ \ \ \ \ (8)")
 = \mathbb{P}_{\mu}(X \in R) \\ = \mathbb{P}_{\mu}(\overline{X} > c) \\ = \mathbb{P}_{\mu}\left( \frac{\sqrt{n}(\overline{X} - \mu)}{\sigma} > \frac{\sqrt{n}(c - \mu)}{\sigma} \right) \\ = \mathbb{P}_{\mu}\left( Z > \frac{\sqrt{n}(c - \mu)}{\sigma} \right) \\ = 1 - \Phi\left(\frac{\sqrt{n}(c - \mu)}{\sigma}\right). \ \ \ \ \ (9)")
) \\ = \underset{\mu \leq 0}{\text{sup}}\left(1 - \Phi\left(\frac{\sqrt{n}(c - \mu)}{\sigma}\right)\right) \\ = \beta(0) \\ = 1 - \Phi\left(\frac{c\sqrt{n}}{\sigma}\right). \ \ \ \ \ (10)")
. \ \ \ \ \ (11)")
}{\sqrt{n}}. \ \ \ \ \ (12)")
 . For a test size of 95%
. For a test size of 95% ")
")
 be \textsc{iid} random variables with
be \textsc{iid} random variables with }") . Let
. Let  be the estimate of
be the estimate of  be the standard deviation of the distribution of
be the standard deviation of the distribution of ")
. \ \ \ \ \ (16)")
 where
where ")
) \\ = \underset{\theta \in \Theta_0}{\text{sup}}\mathbb{P}_{\theta}(X \in R) \\ = \mathbb{P}_{\theta_0}(X \in R) \\ = \mathbb{P}_{\theta_0}(|W| > z_{\alpha/2}) \\ = \mathbb{P}_{\theta_0}\left(\left| \frac{\hat { \theta } - \theta_0 }{\widehat{\textsf{se}}}\right| > z_{\alpha/2}\right) \\ \rightarrow \mathbb{P}(|Z| > z_{\alpha/2}) \\ = \alpha. \ \ \ \ \ (18)")
 and
and  times, respectively, and have a probability of predicting with success as
times, respectively, and have a probability of predicting with success as  and
and  , respectively.
, respectively. .
.")
 versus
versus  is
is  = \frac{ \underset{\theta \in \Theta_0}{\text{sup}} (L( \theta|\mathbf{x} )) }{ \underset{\theta \in \Theta}{\text{sup}} (L( \theta|\mathbf{x} )) }. \ \ \ \ \ (20)")
 components:
components: }") . For
. For  ,
, moment as
moment as  = \mathbb{E}_\theta(X^j) = \int \mathrm{x}^{j}\,\mathrm{d}F_{\theta}(x). \ \ \ \ \ (1)")
")
 is the value of
is the value of  = \hat{\alpha_1} \\ \alpha_2(\hat{\theta_n}) = \hat{\alpha_2} \\ \vdots \vdots \vdots \\ \alpha_k(\hat{\theta_n}) = \hat{\alpha_k} \ \ \ \ \ (3)")
}") . The likelihood function is defined as
. The likelihood function is defined as  = \prod_{i=1}^n f_X(X_i;\theta). \ \ \ \ \ (4)")
 = \log(\mathcal{L}_n(\theta))}") .
. }") .
.}") distribution.
distribution.  = \begin{cases} 1/\theta 0 < x < \theta \\ 0 \text{otherwise}. \end{cases} \ \ \ \ \ (5)")
 and
and  , then
, then  = 0}") . Otherwise
. Otherwise  = (\frac{1}{\theta})^n }") which is a decreasing function of
which is a decreasing function of \} = X_{max}}") .
.  and
and  are \textsc{pdf}, the Kullback Leibler distance between them is defined as
are \textsc{pdf}, the Kullback Leibler distance between them is defined as  = \int f(x) \log \left( \frac{f(x) }{g(x) } \right) dx. \ \ \ \ \ (6)")
}") . Then the score function is defined as
. Then the score function is defined as  = \frac{\partial \log f_X(x; \theta) }{\partial \theta}. \ \ \ \ \ (7)")
 = \mathbb{V}_{\theta}\left( \sum_{i=1}^n s(X_i; \theta) \right) \\ = \sum_{i=1}^n \mathbb{V}_{\theta}\left(s(X_i; \theta) \right). \ \ \ \ \ (8)")
) = 0. \ \ \ \ \ (9)")
) = \mathbb{E}_{\theta}(s^2(X; \theta)). \ \ \ \ \ (10)")
 = nI(\theta). \ \ \ \ \ (11)")
 = -\mathbb{E}_{\theta}\left( \frac{\partial^2 \log f_X(x; \theta) }{\partial \theta^2} \right) \\ = -\int \left( \frac{\partial^2 \log f_X(x; \theta) }{\partial \theta^2} \right)f_X(x; \theta) dx. \ \ \ \ \ (12)")
 } }") .
. }. \ \ \ \ \ (13)")
. \ \ \ \ \ (14)")
}} }") .
. . \ \ \ \ \ (15)")
}") traps
traps  . We call
. We call  is random and
is random and }") .
. be the \textsc{cdf} of a random variable
be the \textsc{cdf} of a random variable  with standard normal distribution and
with standard normal distribution and  \\ \mathbb{P}(Z > z _{\alpha / 2} ) = ( 1 - \alpha / 2) \\ \mathbb{P}(- z _{\alpha / 2} < Z < z _{\alpha / 2}) = 1 - \alpha. \ \ \ \ \ (16)")
 \ \ \ \ \ (17)")
 \rightarrow 1 - \alpha. \ \ \ \ \ (18)")
 is .95,
is .95,  is 1.96 and the interval is thus
is 1.96 and the interval is thus  = \left( \hat{\theta} - 1.96\hat{\textsf{se}} , \hat{\theta} + 1.96\hat{\textsf{se}} \right) }") .
. : \theta \in \Theta\} \ \ \ \ \ (1)")
 = \frac{1}{\sigma\sqrt{2\pi}}exp\{-\frac{1}{2\sigma^2}(x-\mu)^2\}, \mu \in \mathbb{R}, \sigma > 0\} \ \ \ \ \ (2)")
 cannot be parameterized by a finite number of parameters.
cannot be parameterized by a finite number of parameters. is called a statistical functional.
is called a statistical functional.  is given as:
is given as:  = \int x dF(x) \ \ \ \ \ (3)")
 = \int x^2 dF(x) - \left(\int xdF(x)\right)^2 \ \ \ \ \ (4)")
 = F^{-1}(x) \ \ \ \ \ (5)")
,\dotsc,(X_n, Y_n)}") .
.  is assumed to depend on
is assumed to depend on  = \mathbb{E}(Y|X=x) \ \ \ \ \ (6)")
 is finite dimensional, then the model is a parametric regression model, otherwise it is a non-parametric regression model.
is finite dimensional, then the model is a parametric regression model, otherwise it is a non-parametric regression model.  , then we call this regression or curve estimation.
, then we call this regression or curve estimation.  = \mathbb{E}(Y|X=x)}") can be algebraically manipulated to express it in the form
can be algebraically manipulated to express it in the form  + \epsilon \ \ \ \ \ (7)")
 = 0}") .
. : \theta \in \Theta\}}") is a parametric model, then we write
is a parametric model, then we write  = \int_A f_X(x) dx }") to denote the probability that X belongs to A. It does not mean that we are averaging over
to denote the probability that X belongs to A. It does not mean that we are averaging over  . Since
. Since  : Formally, let
: Formally, let  of
of . \ \ \ \ \ (8)")
 = \mathbb{E}( \hat{\theta} ) - \theta. \ \ \ \ \ (9)")
 .
.  = \sqrt{\mathbb{V}(\hat{\theta})}. \ \ \ \ \ (10)")
 = \mathbb{E}_{ \theta } ( \hat{\theta} - \theta)^2. \ \ \ \ \ (11)")
 . Then,
. Then,  = p}") . Hence,
. Hence,  is unbiased.
is unbiased. . \ \ \ \ \ (12)")
}") (where
(where  }") and
and  }") are functions of the data), such that
are functions of the data), such that  \geq 1 - \alpha, \forall \: \theta \in \Theta. \ \ \ \ \ (13)")
 \\ \mathbb{P}(Z > z _{\alpha / 2} ) = ( 1 - \alpha / 2) \\ \mathbb{P}(- z _{\alpha / 2} < Z < z _{\alpha / 2}) = 1 - \alpha. \ \ \ \ \ (14)")
 \ \ \ \ \ (15)")
 \rightarrow 1 - \alpha. \ \ \ \ \ (16)")